
This is a repost from https://medium.com/@kublermdk/advanced-filtering-with-mongodb-aggregation-pipelines-5ee7a8798746 although go read it there so I can get the Medium $$, because it reads better.
For a project Chris Were and I have been working on we discovered a great way of doing advanced queries using MongoDB’s Aggregation pipelines with the use of the $merge operator in order to filter down to a specific set of customers based on their demographics and purchasing behaviour.
For those that don’t know MongoDB’s aggregation pipeline is much more sophisticated and at least for me, also more intuitive than filtering using Map-Reduce.
The project is part of the APIs and admin control panel backend that powers a mobile app for customers who are shopping.
We know things like the customers age, gender, and state.
We save some of the customer’s transaction data, including the storeId, an array of products and an array of product categories. Although only the last few months worth.
We have an admin control panel where the managers can create a set of filters to select a specific customer group, they can then then send push notifications to those customers, assign them coupons or send them surveys.
Except for the number of days ago, the entries allow for multiple selections. e.g You can select all age ranges, just one, or a couple of them.
Although it’d take you a really long time in the UI to select almost all of the products or even the categories. Hence we have both have and haven’t purchased / shopped at versions.
Example filters:
Age: 0–20, 21–30, 31–40, 41–50, 51–60, 60+
Gender: Male, Female, Other
State: South Australia, Victoria, Queensland, New South Wales, Western Australia, ACT, NT
Have Purchased Products [X,Y, …] in the last Z days
Haven’t Purchased Products [X,Y, …] in the last Z days
Have Purchased from Product Categories [X,Y, …] in the last Z days
Haven’t Purchased from Product Categories [X,Y, …] in the last Z days
Have Shopped at Store(s) [X,Y, …] in the last Z days
Haven’t Shopped at Store(s) [X,Y, …] in the last Z days
They needed the system to be flexible so there’s also include and exclude versions of the filters.
Importantly the Include filters are AND’d together whilst the Exclude filters are OR’d together. So you can get very specific with the includes whilst applying some broad exclude filters.
An example might be selecting people who have purchased toilet paper and alcohol hand sanitiser in the last 7 days but exclude all people aged 60+ and all people who’ve purchased kitty litter. A notification can then be sent about how there’s a new pandemic preparedness set which is now in stock, or how the stores are being regularly disinfected during the Covid19 pandemic.
Another option could be to target people in South Australia who are 30 yrs old or under and have purchased from the Deli – Vegan meats product category in the last 10 days, but exclude those who’ve purchased the new Vegan burger. Then they can be given a 2 for 1 voucher for the new burger.
With many thousands of products, hundreds of categories and a few dozen stores there’s a reasonable amount to search through. We also don’t know how many customers there will be as the system hasn’t been launched yet.
But the system has to be fairly fast as we sometimes need to queue up customer push notifications whilst processing the HTTP requests from the 3rd party sending us the transaction information.
The important parts of the data structure looks like this:
What we needed after after filtering all the customers and transactions is a list of Customer IDs. We can then feed those into a variety of systems, like the one for sending push notifications, or selecting which people get coupons.
A main limitation was that whilst the database servers were quite powerful, the web servers weren’t. My initial thoughts were to process an bunch of aggregation pipelines, get a list of CustomerID’s and do the merging and processing in PHP, but when there’s potentially 100k+ customers and transactions, Chris pushed to go harder on the database. Thankfully MongoDB is powerful and flexible enough to do what we wanted.
In the latest v4.2 version of MongoDB there’s now a $merge aggregation pipeline which can output documents to a collection and has some advanced controls about what to do when matching, unlike the $out operator.
I worked out that we can do two types of queries. A “Have” select of all those who should stay and a “Have Not” select of all those who should be removed.
For a “HAVE” Select we output the customerId’s into a merged results collection for the customer group with an extra {selected: true} field and bulk delete those without the selected field, then and bulk-update and removed the selected:true field.
For the Have Not’s we select all the customerId’s of those we don’t want, set {excluded:true} and bulk delete those with the field.
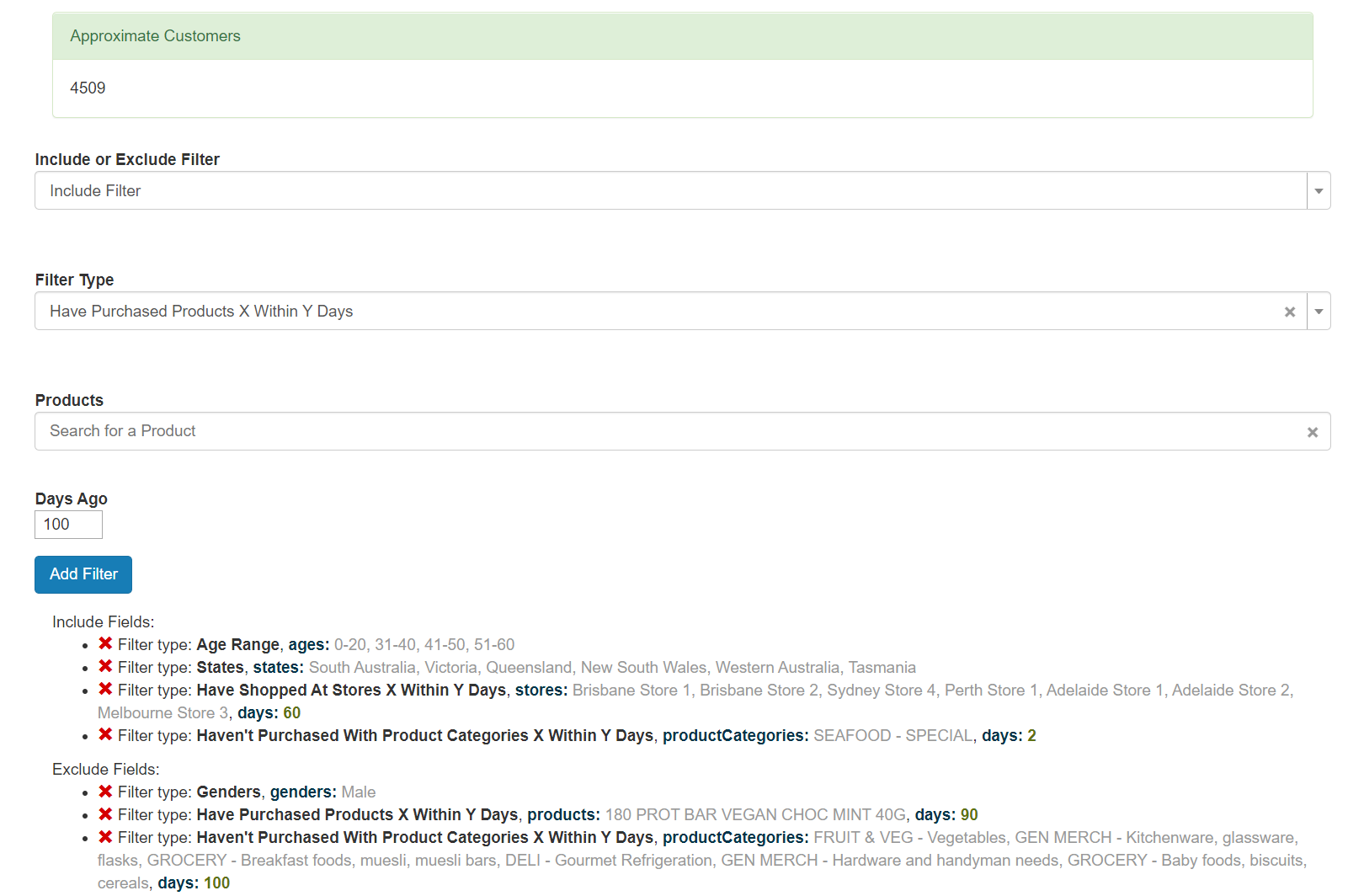
This is an example of the UI for setting the filters. The approximate customer’s is based upon some randomly created data used for load testing… In this instance 17k customers and 340k transactions.
The UI creates a set of filters with the values of things like the productId’s, but the PHP backend, using the Yii2 framework, Mozzler base and some custom code, does some parsing of things like ages. e.g From the string “0–20” to the current unix “time()” to “time() -20 years”. Similar changes are done on the backend to convert something like 60 days ago into a unix timestamp relative to now.
I was going to do an aggregation pipeline for each filter. However if there’s 10 filters that could be a lot of work. MongoDB seems to be better at having somewhat complicated $match queries (with some good indexes) but not so good at running as many aggregations.
Chris then suggested we merge the aggregations and I realised that doing it the following way actually works out perfectly and we only need a max of 4 aggregations. I’m sure if the Exclude filters weren’t considered a logical OR or the Include’s were consider a logical AND of the filters then things would be different.
Aggregation pipelines
1. Customer Select (Have):
Include filters for a Customer’s Age, Gender and/or State
2. Customer Exclude (Have Not):
Exclude filters for a Customer’s Age, Gender and/or State
3. Transaction Select (Have):
Include filters for Have Purchased Products, Categories and/or at Stores
Exclude filters for Haven’t Purchased Products, Categories and/or at Stores
4. Transaction Exclude (Have Not)
Include filters for Haven’t Purchased Products, Categories and/or at Stores
Exclude filters for Have Purchased Products, Categories and/or at Stores
From the admin control panel UI we’ve grouped the filters into the Include or Exclude and have an array of them.
Because things like 7 days ago needs to be converted into unix timestamp based on the current time, we need to update the aggregations dynamically, hence using MongoDB Views wasn’t really possible.
On the backend I wrote a Customer Group manager system for grouping the filters into the different categories and merging them together.
Whilst the actual queries we did were a bit more complicated than shown below because we aren’t saving the state as a string but a postcode so have a bunch of ranges for them, what we do is very similar to the example aggregation below, based on the filters in the UI screenshot:
The aggregations in the above Gist should have enough comments to explain the actual steps in detail. But it’s expected you’ve used MongoDB’s aggregations to have some idea of what’s going on.
Some points we discovered:
- The $merge filter lets us put all the data into a merged collection and we can iterate over the results using a cursor, use the collection count and other things to make it both easy and very scalable. The merged collections are effectively free caching.
- It was very powerful to always be doing a $match (select) query first. It’s fast with the right indexes and powerful with the excluded or selected: true and doing a bulk delete / update.
- Merging into the Have / Have Not filtersets on the Customer and Transaction models mean there’s a maximum of 4 pipelines that will be run. Although if the Exclude filters were an AND not OR between them, then this might not be the case.
- An edge case is that we have to add in all customerId’s as a first pass if there wasn’t a Customer Have pipeline so that customers who don’t have any transactions could still be returned, or so that if there’s no filters then it selects everyone.
- I also developed some tweaks which let us run a set of filters on just a single customer or small selection of customers to know if they are part of a customer group. This is especially used when a new transaction comes in. We point to a different (temporary) customerGroup collection in that case. Obviously querying against a small set of customerIDs makes things much faster.
The end results are good. I get around 600ms when querying against 20k customers and 180k transactions with the basic Vagrant VM on my laptop. Although that is random data I generated just for load testing.
We are still waiting to see what this will be like in production.
Let me know if something doesn’t make sense or if you want more information.
1 comment