

At both the Global ZDay event in Brisbane, Australia the New Zealand ZDay event in Auckland in 2017 and at the Global Zday event in Frankfurt, Germany in 2018 I gave this presentation about the Price of Zero transition to a Natural Law Resource Based Economy. The slides are based on the presentation given on… Continue reading ZDay presentation – Price of Zero Transition to an RBE
Verida was too early, merged with Kwaai
What did Verida merge with? https://www.kwaai.ai/ That’s the thing I keep wanting to lookup but find hard. Context: Verida was a Crypto project so you could own your own data. Unfortunately it failed in late 2025 The idea was that you’d connect your various 3rd party services, Facebook, Health app, Spotify. All your data could… Continue reading Verida was too early, merged with Kwaai
Cards, Cables, Concrete: A Mental Model for Understanding How Hard Something Is to Change
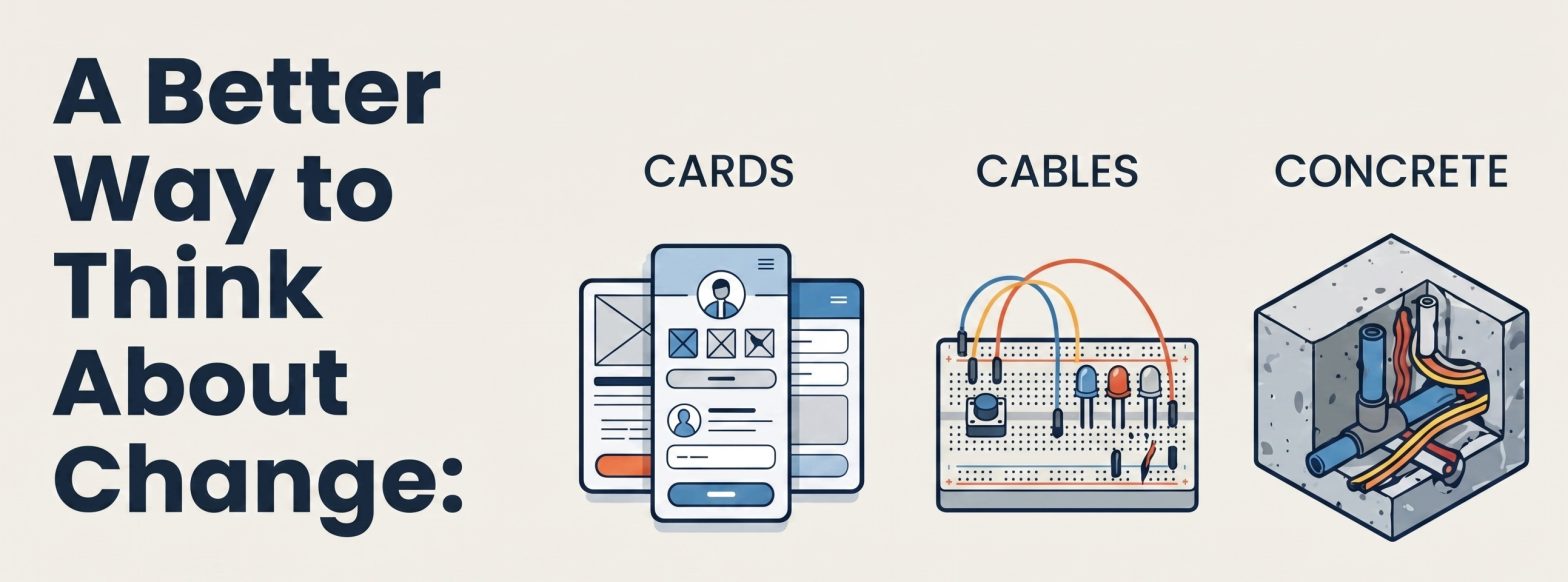
By Michael Kubler | kublermdk.com TLDR Cards, Cables, Concrete is a three tier mental model for gauging how much effort it takes to change something. Use it to ask: “Is this change a card, cable, or concrete situation?” before committing time, money, or people. The Problem This Solves Every decision sits somewhere on a spectrum… Continue reading Cards, Cables, Concrete: A Mental Model for Understanding How Hard Something Is to Change
Book Summary – Thinking in Systems by Donella Meadows

The Book Thinking in Systems by Donella Meadows is a good read. I highly recommend it for anyone as a good introduction to Systems Thinking. It was easy for me to understand and wasn’t as conceptually hard to process as The Unaccountability Machine which focused more on Stafford Beer’s Viable Systems Model. This book seems… Continue reading Book Summary – Thinking in Systems by Donella Meadows
Better AI Prompting quick tips
So I’ve read the Claude, Meta and some of the other models prompting guides but I think the YCombinator video they just released explains them well. If you are creating an AI prompt for something even a little complex then you should ask it first to provide a better prompt. This is called Meta Prompting.… Continue reading Better AI Prompting quick tips
Plesk – Mod Security Web Application Firewall Comodo rules explained

If you’re using Plesk with ModSecurity and the free Comodo ruleset, understanding the rule categories is essential for effective website security. These rules protect your site from threats like SQL injection, cross-site scripting (XSS), brute force attacks, information disclosure, and protocol violations. Comodo’s ruleset also includes specialized protections for popular platforms like WordPress, Joomla, and Drupal, as well as safeguards against backdoors and malicious bots. While these rules provide robust security for your web applications, some—such as those targeting PHP information disclosure—can be overly sensitive and may require customization to prevent false positives and ensure smooth website functionality. Properly configuring ModSecurity in Plesk helps balance strong security with optimal site performance.
The 20 Lessons on Tyranny
The 20 Lessons on Tyranny 1. Do not obey in advance – Don’t voluntarily surrender power by anticipating what authoritarian leaders might want. 2. Defend institutions – Protect democratic institutions like courts, newspapers, laws, and labor unions through active participation. 3. Beware the one-party state – Support multi-party systems and democratic elections; consider participating in… Continue reading The 20 Lessons on Tyranny
Claude – Some complaints and suggestions

I’ve been using and paying for Claude the AI by Anthropic for a while now and there’s some things that bug me about it. Firstly, I’ll mention that I love Claude. The output is detailed and useful. I use Claude for thinking through hard problems. Sometimes directly, sometimes in Perplexity or Cursor. I OFTEN use… Continue reading Claude – Some complaints and suggestions
The Dictator’s Handbook – Summary
The Dictator’s Handbook and The Rules for Rulers: A Summary Both “The Dictator’s Handbook” by Bruce Bueno de Mesquita and Alastair Smith and CGP Grey’s video “The Rules for Rulers” (based on the book) present a powerful framework for understanding political power called selectorate theory. This summary is provided by Claude. Core Principles At the… Continue reading The Dictator’s Handbook – Summary
Key Concepts from Yuval Noah Harari’s “Nexus”

Summary of “Nexus” by Yuval Noah Harari This is a summary generated by Google’s Gemini 2.0 Flash Thinking model. It was given an 833KB transcript based on a Whisper AI Speech to Text of the Audiobook of Nexus.I couldn’t use Claude, my usual go-to because there was so much content it was beyond the acceptable… Continue reading Key Concepts from Yuval Noah Harari’s “Nexus”
Summary of Flow by Mihaly Csikszentmihalyi
The Path to Flow: Key Insights from Mihaly Csikszentmihalyi’s Work on Optimal Experience This post is a Claude generated summary of the book Flow: The Psychology of Optimal Experience by Mihaly Csikszentmihalyi Have you ever been so completely absorbed in an activity that you lost track of time, forgot your worries, and felt a deep… Continue reading Summary of Flow by Mihaly Csikszentmihalyi