

If you’re using Plesk with ModSecurity and the free Comodo ruleset, understanding the rule categories is essential for effective website security. These rules protect your site from threats like SQL injection, cross-site scripting (XSS), brute force attacks, information disclosure, and protocol violations. Comodo’s ruleset also includes specialized protections for popular platforms like WordPress, Joomla, and Drupal, as well as safeguards against backdoors and malicious bots. While these rules provide robust security for your web applications, some—such as those targeting PHP information disclosure—can be overly sensitive and may require customization to prevent false positives and ensure smooth website functionality. Properly configuring ModSecurity in Plesk helps balance strong security with optimal site performance.
Category: geeky
Computers, Programming or Technical things.
Claude – Some complaints and suggestions

I’ve been using and paying for Claude the AI by Anthropic for a while now and there’s some things that bug me about it. Firstly, I’ll mention that I love Claude. The output is detailed and useful. I use Claude for thinking through hard problems. Sometimes directly, sometimes in Perplexity or Cursor. I OFTEN use… Continue reading Claude – Some complaints and suggestions
Stripe Mock Testing in PHP
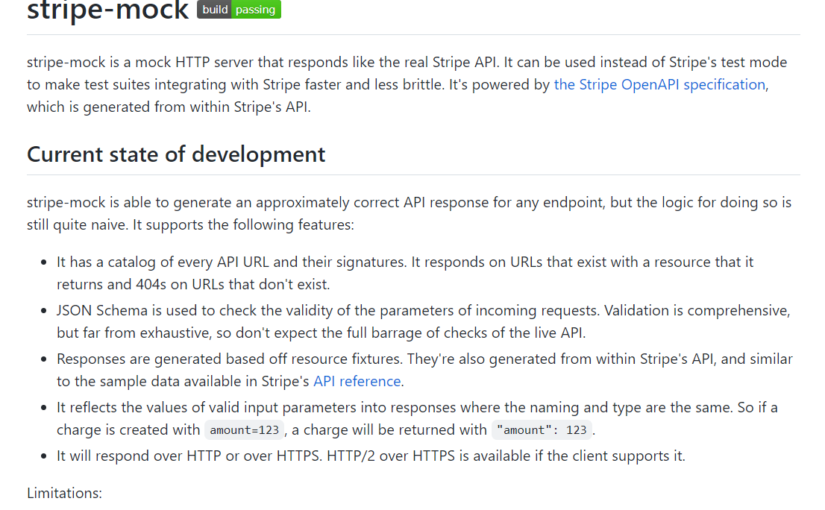
Stripe Mock Testing in PHP.
Make sure the Go version is up to date, the Stripe Client has the api_base set and the CURLOPT_SSL_VERIFYPEER is set to 0 for the curl client.
Disable ESET Self-Defense to Shrink your Windows volume
As you can tell from the title, if your trying to Defrag your hard drive, shrink the volume or something like that you might have issues when you have the ESET security software (Anti-virus) installed. It took me a while and involved trawling online forums but I found the best option is to open up… Continue reading Disable ESET Self-Defense to Shrink your Windows volume
Using jq to update the contents of certain JSON fields
OK, I’ll be brief. I created a set of API docs with Apiary using Markdown format. We needed to change over to Postman, so I used Apimatic for the conversion. Which was 99% great, except for the item descriptions it only did a single line break, not two line breaks. As Postman is reading… Continue reading Using jq to update the contents of certain JSON fields
My ~/.bash_aliases 2017
I have a base ~/.bash_aliases file which I normally use Ansible to update on various servers when needed and thought I’d share it. This is intended for sys admins using Ubuntu. [ Download the bash aliases file here ] The main aliases are : ll – I use this ALL the time, it’s `ls -aslch` and shows the… Continue reading My ~/.bash_aliases 2017
Initial Ansible Install on Ubuntu
Because I have to run this on any new Ansible or Vagrant machine, here’s a note to myself to make this a little faster. For Ubuntu Linux machines sudo apt-get –assume-yes install nano man git python # For a new, minimal install of Ubuntu, e.g a Vagrant Box, they don’t even include a ~/.bashrc file nor nano… Continue reading Initial Ansible Install on Ubuntu
Synology NAS – Start with the smaller drives first
When you are setting up a Synology NAS, such as the 8 bay ( DS1815+ ) system I got, you’ll want to start with your smallest drive first and add larger ones over time. If you start with your biggest drive, you won’t be able to make use of the smaller ones. The reason is best… Continue reading Synology NAS – Start with the smaller drives first
Windows 10 Anniversary update broke Vagrant
If you are like me and use a Windows machine to do web development on, but use a Linux Vagrant virtual machine, then you likely had issues with the virtual box VM not working after the Windows 10 Anniversary update. I found that after spending hours waiting for Windows 10 to update, my usual vagrant… Continue reading Windows 10 Anniversary update broke Vagrant
Don’t Use Google Authenticator

Update: Google Authenticator has now been updated and does sync to your cloud and you can much more easily import/export. In the mean time Authenticator Plus has been deprecated and is no longer a useful alternative. It’s cloud sync capabilities don’t work properly anymore and when you export, the categories aren’t saved and the search… Continue reading Don’t Use Google Authenticator