
Here’s a general look at my year of 2020. The year that started off with epic bushfires in Australia, the Taal volcano in Philippines erupting and will be known as the year of Covid19. There was the massive explosion in Beirut, even brain eating amoebae in a part of the US water supply, the Arecibo… Continue reading 2020 – A year in review
Year: 2020
Google AutoML Prediction with a Google Cloud Storage source
As per the Gist https://gist.github.com/kublermdk/0b8c1f6173e5b121e5aee303160fa3f3
Reinvigorating TZM
At a meeting last night, Friday the 10th of July 2020 about 15 TZM members had a discussion on Team Speak about trying to reinvigorate the movement.There was lots of ideas. But a couple of people’s suggestions were on approaches to working out the best option instead of just ways to make TZM great again.Aaron… Continue reading Reinvigorating TZM
Disable ESET Self-Defense to Shrink your Windows volume
As you can tell from the title, if your trying to Defrag your hard drive, shrink the volume or something like that you might have issues when you have the ESET security software (Anti-virus) installed. It took me a while and involved trawling online forums but I found the best option is to open up… Continue reading Disable ESET Self-Defense to Shrink your Windows volume
Advanced Filtering with MongoDB Aggregation Pipelines
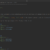
This is a repost from https://medium.com/@kublermdk/advanced-filtering-with-mongodb-aggregation-pipelines-5ee7a8798746 although go read it there so I can get the Medium $$, because it reads better. For a project Chris Were and I have been working on we discovered a great way of doing advanced queries using MongoDB’s Aggregation pipelines with the use of the $merge operator in order… Continue reading Advanced Filtering with MongoDB Aggregation Pipelines
Via Negativa
Via Negativa translates to “by removal.” Taleb argues that a lot of problems can be solved by removing things, and not by adding more. In decision making, if you have to come up with more than one reason to do something, it’s probably because you’re just trying to convince yourself to do it. Decisions that… Continue reading Via Negativa
Covid19 – It’s not intentional, it’s neglect

I’ve been seeing conspiracy theories pop up saying that the Covid19 Corona virus is an intentionally created virus.But in my research the truth is that it seems to be a string of incidents going back to the 1960’s and culminating in neglect of animals. Firstly, I know that in Australia at least government funding cuts… Continue reading Covid19 – It’s not intentional, it’s neglect
Evernote lost my work
TLDR: Evernote doesn’t seem to backup your work whilst writing. It doesn’t save until you’ve actually exited the note. So it’s highly vulnerable to your phone / tablet dying. The Story This afternoon I got my Android Tablet out and started to write up my weekly review. I haven’t actually done my review for the… Continue reading Evernote lost my work